

Un algoritmo de DeepMind es capaz de cooperar y jugar a nivel competitivo en un entorno 3D en primera persona.
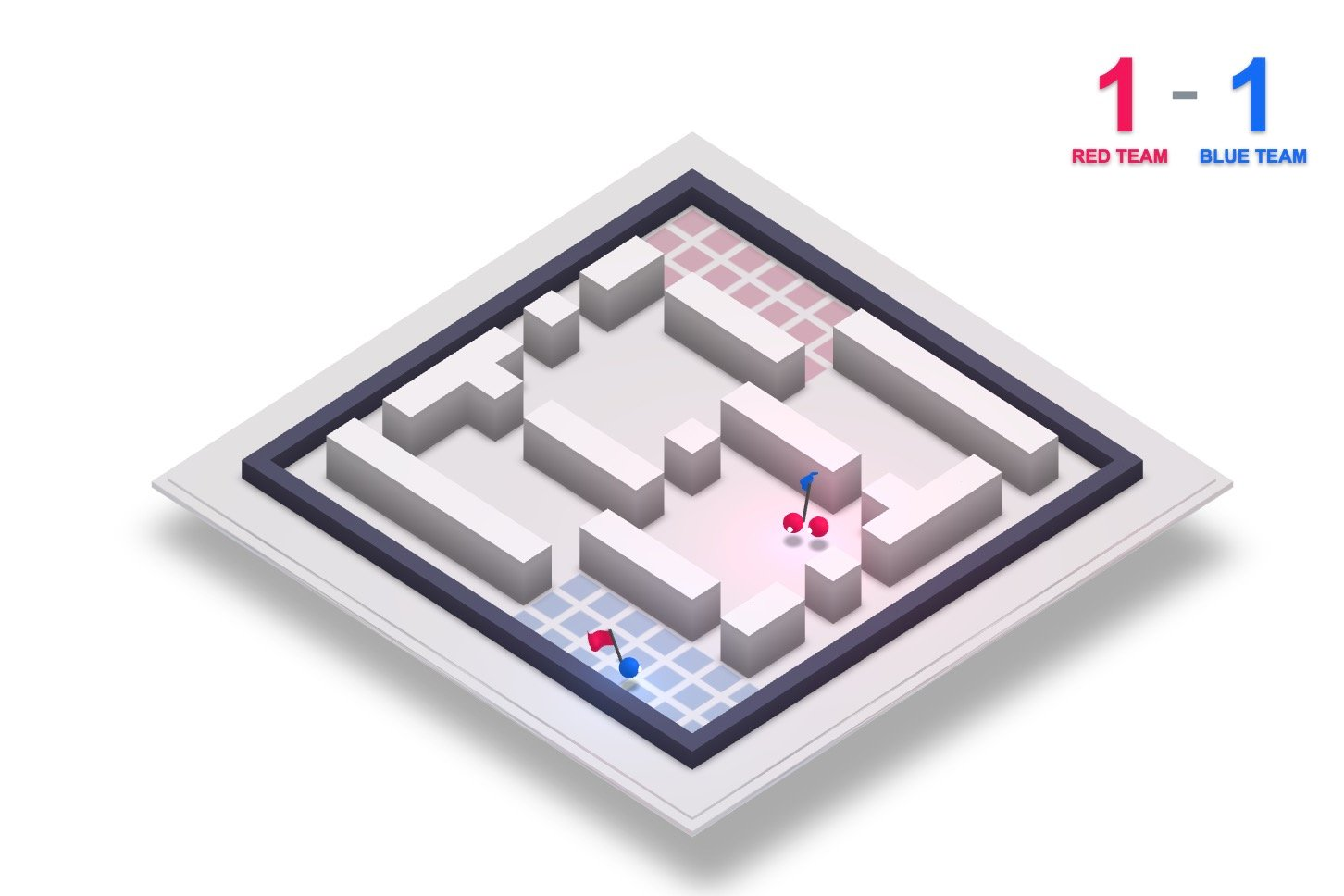
 Representación de los agentes de inteligencia artificial jugando a una versión modificada del videojuego Quake III Arena (DeepMind)
Representación de los agentes de inteligencia artificial jugando a una versión modificada del videojuego Quake III Arena (DeepMind)
La inteligencia artificial ha vuelto a superar a los humanos en un campo en el que hasta hace poco parecía casi imposible: los videojuegos multijugador en tres dimensiones.

Un algoritmo de la empresa de Google DeepMind ha derrotado a la mayoría de sus oponentes humanos, jugadores profesionales, en el clásico Quake III Arena, que en 1999 sentó las bases de los videojuegos multijugadores 3D en primera persona. Los resultados, publicados hoy en la revista Science , demuestran que la inteligencia artificial ya es capaz de aprender estrategias avanzadas de cooperación sin ayuda humana para cumplir objetivos en ambientes complejos.
Hasta ahora, la inteligencia artificial, de la mano de la propia DeepMind, había logrado superar a los mejores jugadores de juegos de mesa como el go, el ajedrez o el shogi. Sin embargo, los videojuegos multijugador se consideraban un terreno demasiado difícil, dada la necesidad de coordinación entre jugadores y de desplazarse por un ambiente en tres dimensiones.
Sin ayuda humana
El algoritmo For The Win se entrenó jugando 450.000 partidas contra sí mismo
Ahora, los investigadores de DeepMind han creado un algoritmo capaz de jugar a una versión modificada del videojuego Quake III Arena, del que a día de hoy todavía se celebran torneos profesionales. En concreto, lo entrenaron en un modo de juego en el que dos equipos compiten para capturar banderas de una base rival en mapas aleatorios. Los jugadores deben cooperar para llegar a la base enemiga y proteger la propia; cuando un jugador recibe un disparo de un enemigo, la bandera que haya cogido cae al suelo y vuelve automática a su propia base.

El algoritmo, al que los desarrolladores apodaron For The Win (abreviado FTW, en alusión a la expresión inglesa utilizada en internet y en la comunidad gamer para manifestar agrado por algo), se entrenó jugando 450.000 partidas contra 30 versiones de sí mismo, sin ningún tipo de ayuda externa. “Nadie les enseñó a jugar al juego”, remarca en un comunicado Max Jaderberg, investigador de DeepMind y primer autor de la investigación.
La máquina desarrolló estrategias propias de jugadores humanos avanzados
Cada una de las versiones, llamadas agentes, sólo veía los píxeles de la pantalla y la puntuación de la partida en cada momento, la misma información que tiene un jugador humano. “Lo que hace estos resultados tan emocionantes es que estos agentes perciben el ambiente desde una perspectiva de primera persona, exactamente como haría un jugador humano”, declara en el mismo comunicado Thore Graepel, investigador de DeepMind y director del trabajo.
 Representación de la vista en primera persona de los jugadores o algoritmos For The Win en la versión modificada de Quake III Arena (DeepMind)
Representación de la vista en primera persona de los jugadores o algoritmos For The Win en la versión modificada de Quake III Arena (DeepMind)
Durante el entrenamiento, los agentes For The Win desarrollaron estrategias propias de jugadores humanos avanzados, como esperar cerca de la base enemiga a que salgan nuevas banderas, quedarse en la propia base para defenderla o seguir la trayectoria de compañeros del mismo equipo.
En un torneo con 40 jugadores experimentados, los humanos sólo derrotaron al algoritmo For The Win en un 21% de las partidas
Para poner las capacidades del algoritmo a prueba, DeepMind organizó un torneo de Quake III Arena con cuarenta jugadores experimentados, además de los agentes de inteligencia artificial.

Humanos y algoritmos formaron equipos al azar para enfrentarse entre sí –los investigadores incrementaron el tiempo de respuesta de For The Win para equipararlo a los reflejos de los jugadores humanos y hacer el torneo más justo–. En total, los equipos en los que participaban humanos sólo ganaron en un 21% de las partidas.
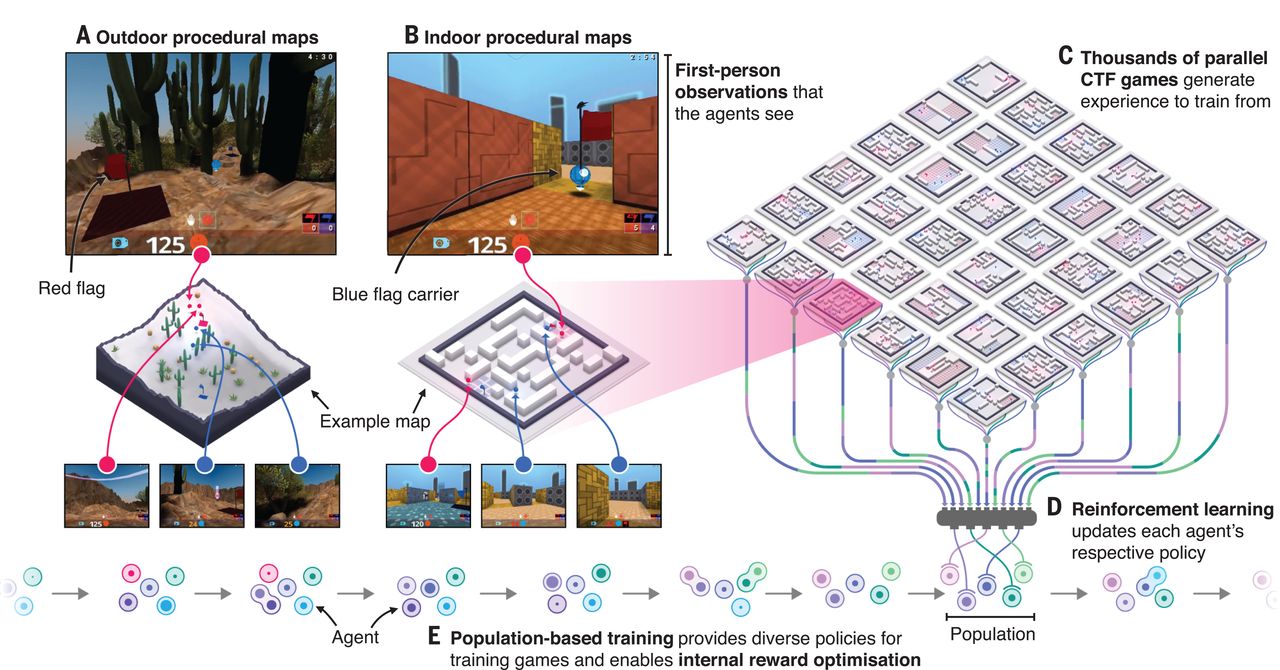 CTF tareas y marco de capacitación computacional
CTF tareas y marco de capacitación computacional
“La motivación subyacente a este trabajo era entender mejor cómo podemos lograr un rendimiento robusto en ambientes complejos con múltiples agentes”, subraya Max Jaderberg.
Los científicos de DeepMind trabajan ya en nuevos algoritmos que puedan jugar a otros modos competitivos de Quake III Arena y a otros videojuegos multijugador.

Google tiene más grandes aspiraciones en mente que dominar los videojuegos y el objetivo de DeepMind, hasta donde sabemos, no es ni destruir ni conquistar el mundo, sino desarrollar una inteligencia artificial para desenvolverse en tareas más complejas y continuar mejorando su modelo actual de aprendizaje, reforzando los métodos de capacitación basados en la población para desarrollar aún más la Inteligencia Artificial. Pero Bueno, tal vez, la proxima vez que hagamos Matchmaking(Formar Equipo del mismo nivel) en un juego, no nos demos cuenta, que nuestro equipo este formado por IAs.
Hasta la próxima

«Hay mayor realidad que nuestra mayor ficción»
Maestro Nori-El
